목차
LOD 란?
개방형 연결 데이터라 불리는 LOD에 대해 알아보겠습니다.
LOD는 웹(World Wide Web)의 창시자 팀 버너스 리(Tim Berners-Lee)가 2006년 제안하였습니다. 이름에서 알 수 있듯이 Linked Open Data는 Linked Data 와 Open Data를 더한 것으로 연결과 개방이 핵심입니다.
지금까지의 웹은 문서의 웹(Web of Document)였습니다. 이것을 기계가 이해할 수 있도록 데이터의 웹(Web of Data)를 만드는 것이 목표입니다. 이렇게 한다면 수많은 문서들을 사람들이 하나하나 모두 확인해서 원하는 정보를 찾는 것이 아니라 Query를 작성하면 원하는 데이터를 얻을 수 있게 됩니다.
Five Star Open Data
LOD를 만들기 위해서는 정보가 모두 공개되어 있어야 합니다. 만약 우리가 PDF Reader가 없으면 PDF 문서를 읽을 수 없고, HWP Viewer가 없으면 HWP 문서를 읽지 못합니다. 그래서 해당 문서를 읽기 위해 프로그램을 따로 설치 합니다. 이렇게 웹상에 데이터가 있더라도 쉽게 읽거나 확인하지 못하기 때문에 팀 버너스리는 데이터 개방 단계를 별을 이용하여 표현 하였습니다.

- 첫 번째 단계 OL은 On-Line의 약자로 온라인에서 활용 가능한 상태의 데이터 입니다. 대표적인 형태가 PDF라 할 수 있습니다.
- 두 번째 단계는 RE 로 machine REadable 상태 입니다. 말 그대로 기계가 읽을 수 있는 형태로 대표적인 예가 엑셀 입니다. 엑셀은 구조화 되어 있어 데이터의 수집, 계산, 시각화등이 가능합니다.
- 세 번째 단계 OF는 Open Format 입니다. 엑셀이나 PDF가 아닌 개방형 데이터로 저작권 문제가 없고, 누구나 사용 가능한 형태를 말합니다. 대표적인 예로는 CSV가 있습니다.
- 네 번째 단계 URI는 Uniform Resource Identifier로 우리가 아는 웹의 URL과 비슷하지만 조금 다른 RDF로 되어 있는 데이터 입니다. RDF는 뒤에서 좀 더 자세히 알아보겠습니다.
- 마지막 다섯 번째가 바로 Linked Data 상태입니다. 팀 버너스 리가 말하는 데이터의 웹 상태를 뜻합니다.
위에서 말한 5가지 단계중 세 번째 단계까지는 이해하기 쉽지만 네 번째 단계부터는 익숙하지 않은 개념이 등장합니다. 바로 RDF 입니다.
RDF란?
RDF는 Resource Description Framework의 약자로 LOD 데이터를 표현하기 위한 기본적인 구문 약속입니다. 기계가 이해할 수 있도록 SPO 구조로 구성되어 있습니다. SPO는 주어(Subject), 술어(Predicate), 목적어(Object)로 구성되어 있습니다. 쉬운 예로 아래와 같은 관계를 가지고 있다고 생각하면 됩니다.
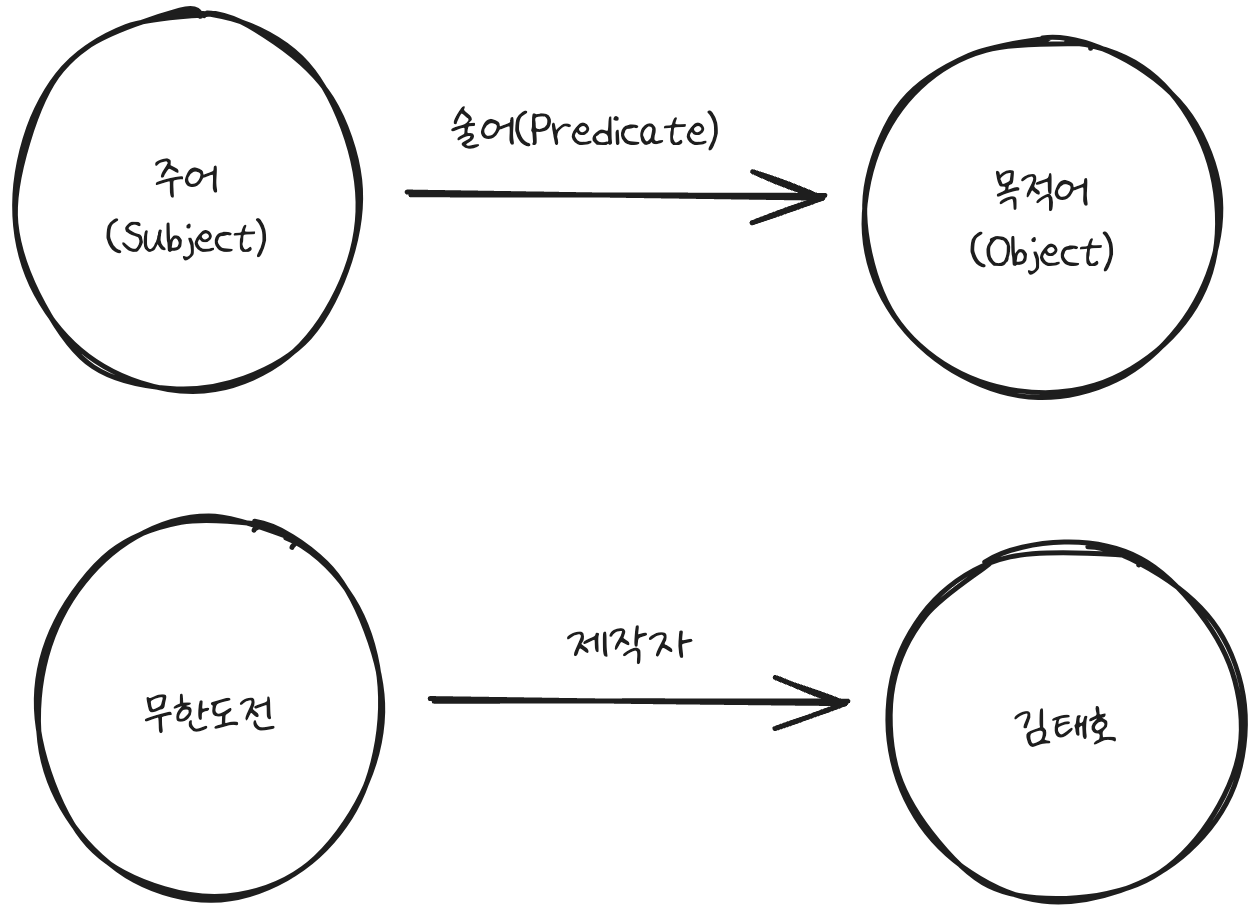
이와 같이 SPO 단계로 구성한다고 해서 기계가 쉽게 알아듣는 것은 아닙니다. 좀 더 이해하기 쉽게 만들기 위해 URI(Uniform Resource Identifier)를 사용합니다. 무한도전, 제작자, 김태호등을 웹상에서 사용할 하나의 개체로 표현해 줍니다. 그럼 위의 관계가 아래와 같이 표현할 수 있습니다.
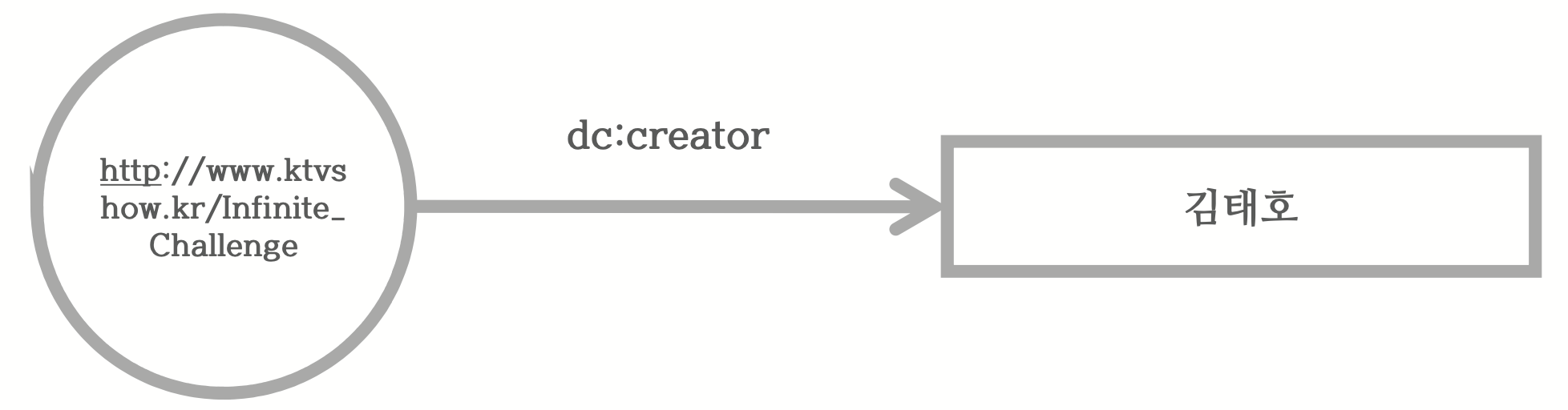
이렇게 표현하면 이전꺼보다 사람이 이해하기는 어려워졌지만 기계가 이해하기에는 훨씬 좋아졌습니다.
SPARQL
이와같이 RDF로 데이터 표현을 하였다면 SPARQL로 데이터를 조회할 수 있습니다. 마치 RDF가 테이블이고 웹상의 문서를 이 테이블의 데이터로 만들어 주었다면, SPARQL은 SQL과 같다고 생각하면 될 것 같습니다. SPARQL은 Simple Protocal and RDF Query Language의 약자로 웹에서 필요한 정보들을 조회하고 반출할 수 있게 됩니다.
LOD 구축 4원칙
지금까지 웹상의 데이터를 LOD를 만드는 단계를 알아보았습니다. 먼저 Five Star Open Data로 데이터를 어떻게 구성해야 하는지 알아보았습니다. 여기서 4, 5단계를 구성하기 위해서는 모든 웹상의 문서들을 데이터화 할 필요가 있었고, 그것을 RDF 형태로 데이터를 만들고 SPARQL 의 Query로 조회한다고 하였습니다. 이런 LOD를 만들기 위해서 팀 버너스 리는 링크드 데이터의 구축 4원칙을 제시하였습니다.
- URI사용. 개별 문서에 존재하는 개별 객체에 각각 URI를 부여하여 웹상에서 특정 개체나 개념을 고유하게 식별 가능하게 합니다.
- HTTP 프로토콜을 사용합니다. 웹을 가능하게 한 핵심 기술인 HTTP를 활용하여 웹상에서 발전하도록 합니다.
- RDF, SPARQL을 사용하도록 합니다. RDF를 통해 데이터를 표현하고, SPARQL로 데이터를 가져옵니다.
- 데이터들을 Link(연결) 합니다.데이터 개체간 연결은 데이터 웹을 더욱 풍성하게 만들어 줄 수 있습니다.
정리
간단하게 LOD에 대해 알아보았습니다. 국내에서도 여러 정보들을 LOD 형태로 만들어 제공하고 있습니다. 국가가 제공하는 정보를 통해 여러가지 서비스를 활용하거나, 만들 수 있습니다. 생성형 AI가 발전한 지금 LOD가 과연 필요할까 라는 생각이 듭니다. 자연어로 기술되어 있어도 충분히 잘 이해하는 수준까지 왔기 때문에 기계어와 비슷하게 만들 필요가 없어보입니다. 하지만 이런 LOD가 있었기에 생성형 AI가 좀 더 자연어를 이해하는데 도움을 주지 않았을까 생각하게 됩니다.
'IT 지식 > 데이터베이스' 카테고리의 다른 글
| CAP 이론 (0) | 2023.12.14 |
|---|---|
| NoSQL(Not Only SQL) (0) | 2023.12.13 |
| 데이터베이스 정규화 (0) | 2023.12.10 |
| 데이터 베이스 이상현상(Anomaly) (2) | 2023.12.07 |
| 데이터 베이스의 고립화 단계(Isolation Level) (0) | 2023.12.06 |

